

Inspired by Command School from Enders Game, let’s make swarms that we can control with our voice! We will do this by having a voice-to-text program feed our voice commands into an LLM, and then that LLM can run a bunch of commands to control the swarm.
Below is the final result.
And we will make this in two parts:
- First we will create a general voice-controller that can plug into any application that supports the Model Context Protocol (MCP). As an example, we will make a canvas application where the LLM can draw shapes on a canvas and move the shapes around, allowing us to “draw” with our voice.
- Then we will make a swarm simulation with a large set of commands which allow the LLM to direct the swarms according to our commands.
Voice-Controller
The overall architecture for how users interact with the simulation will be as follows: the player holds down a button to speak a command, which gets transcribed using a voice-to-text model. The transcription is sent to an LLM agent connected to an MCP server. That server controls the simulation, meaning the agent can directly interact with the simulation using any available tools implemented on the server.

One neat aspect of this architecture is that the voice-controlled agent is independent of the application running on the MCP server. This means we can reuse the voice-controlled agent for any MCP-compatible application. In fact, we’ll develop the voice-controlled agent only once and then use it to interact with multiple MCP servers.
As an example, we create a fairly simple MCP server below.
Canvas MCP Server
We create a canvas that can show squares and circles. We create a few simple functions on the canvas that the LLM can call, then the LLM will be able to turn the voice commands we say into actual function calls on the canvas.
Here are the commands we provide, which in the language of LLM agents are called the ‘tools’.
create_circlecreate_squaremove_shapesremove_shapesget_canvas
It’s essential to write good documentation for each tool, as this is what the LLM will read when choosing what actions to take. I found that including example inputs, expected ranges, and typical values can help to improve its performance. All the code for this project can be found on GitHub.
And once we have the server running and a voice-controller connected to it, we get the below.
The agent can make dumb mistakes, but it can also sometimes be surprisingly clever. One funny interaction I had: Everything seemed to be working correctly, but then I noticed I had forgotten to implement the remove_shapes function. This was weird since the agent seemed to be removing shapes when I asked. It turns out that when the agent couldn’t find a tool to remove the shapes, it would decide to move the shapes off the side of the screen so I couldn’t see them anymore, which made it look like the non-existent remove_shapes function was working just fine.
And now that we can see how we can control a canvas with our voice, we can do the same with a swarm simulation. But that requires writing a sufficiently capable swarm simulation, as well as the tools to allow the LLM to convert our commands into actual actions.
Swarm Simulation
The individual agents of a swarm (or fleet, we will use the terms interchangeably) will be controlled using a modified version of the boids algorithm along with a seeking rule that points each boid toward its target. We only use the separation rule and alignment rule from the boids algorithm, but modified as below.
- Separation: The separation strength between boids of the same swarm will be stronger then between boids of different swarms. This lets different swarms easily pass through each other.
- Alignment: the boids will try to align in the opposite direction of their neighbors, making our swarms are more chaotic. This might help boids more easily move through each other, but mostly I just think this looks cooler.

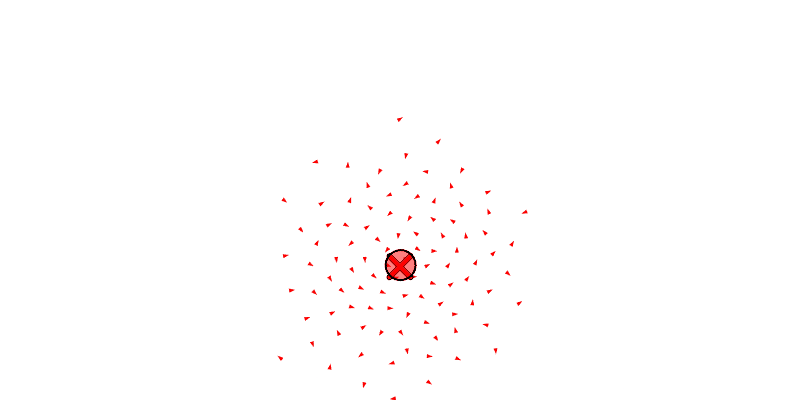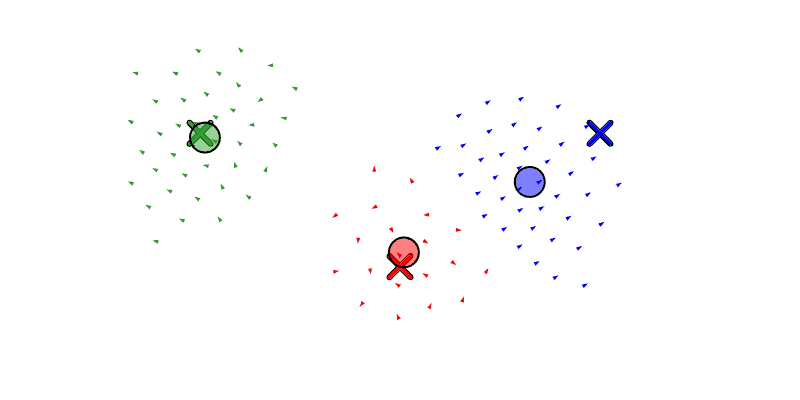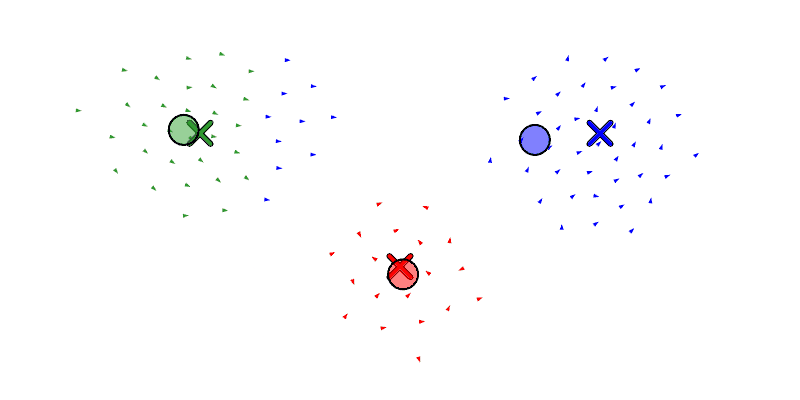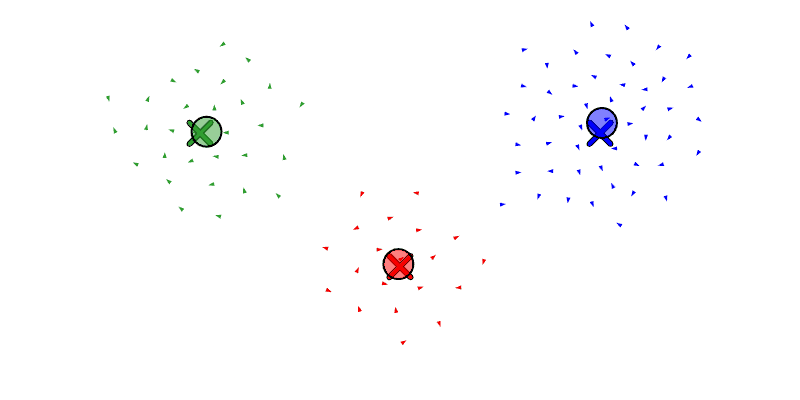
We see each boid as a triangle, the center of mass of all the boids as a circle, and the target position of the swarm as an X.
One of the first tools we will implement is the assign_swarm_to_position function, which lets the agent set the desired position of the swarm. Some variants we can add are assign_swarm_to_follow and assign_swarm_to_waypoints, where assign_swarm_to_follow attaches the swarms target position to some other object that may be moving, and assign_swarm_to_waypoints has the swarm cycle (or just iterate once) through a list of positions.
Below we see the left swarm following a car that is traveling in a circle, and on the right we see a swarm cycling through two waypoints.
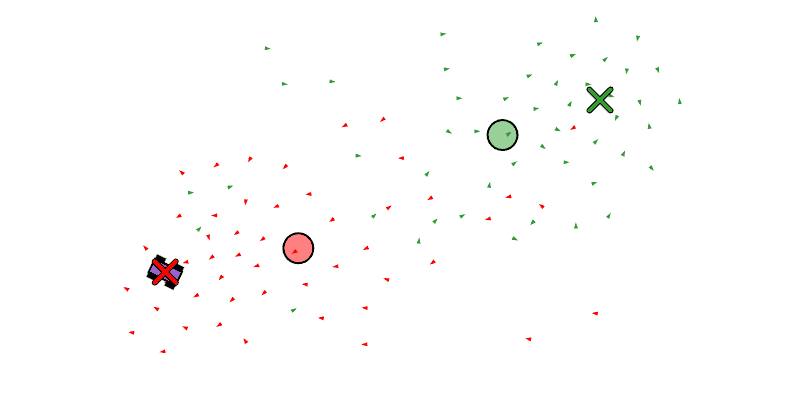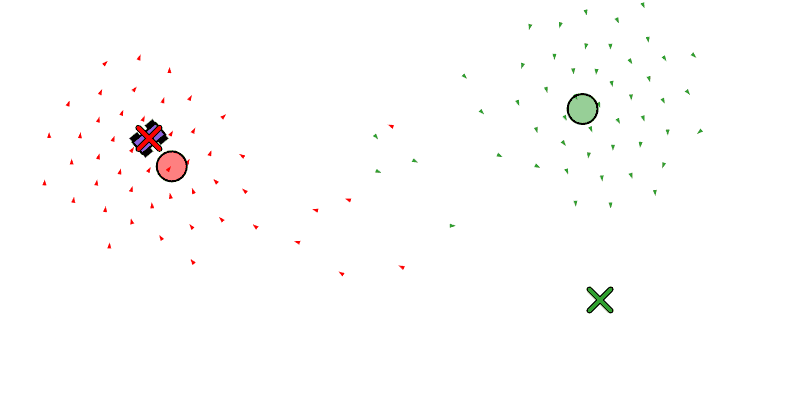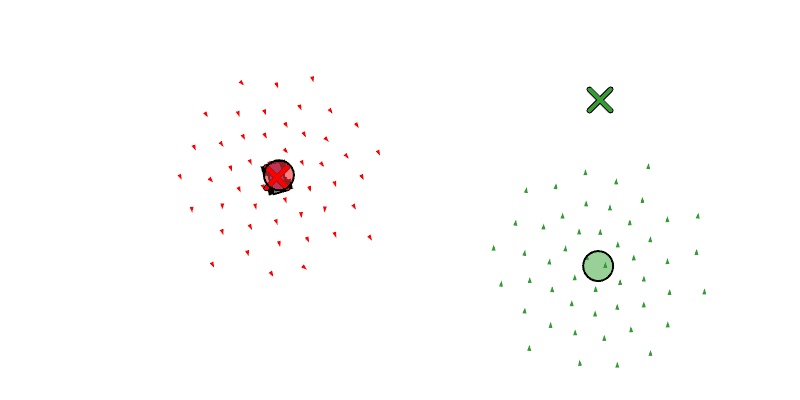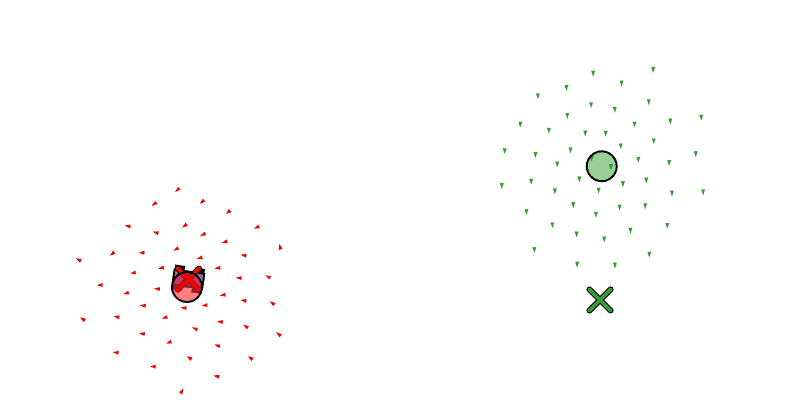
We also want the swarm to be capable of splitting into multiple swarms that can pursue different tasks. We will have the primitives fork_swarm_to_position, fork_swarm_to_follow, and fork_swarm_to_waypoints, all similar to the assignment primitives, but forking off of a pre-existing swarm by taking some of its boids.
We will also let the agent move drones between swarms with reassign_drones, and merge a swarm into another with merge_swarm (but to be honest, merge_swarm may not be necessary since it is just a specific instance of reassign_drones where it re-assigns all the drones). Below we see a swarm get forked to the left and then right, and then re-assign some boids from the left swarm to the right.
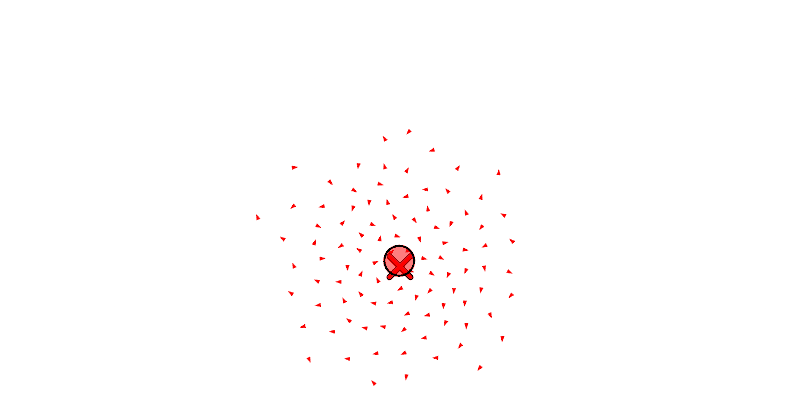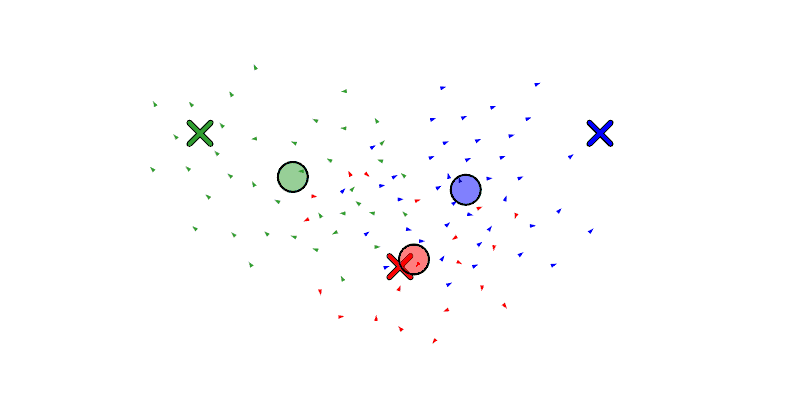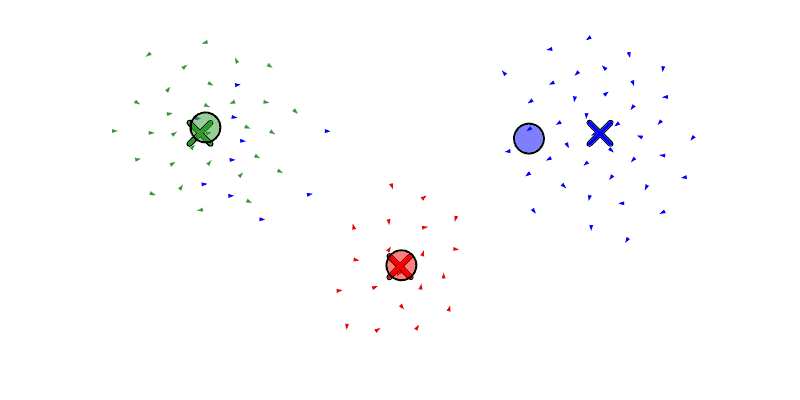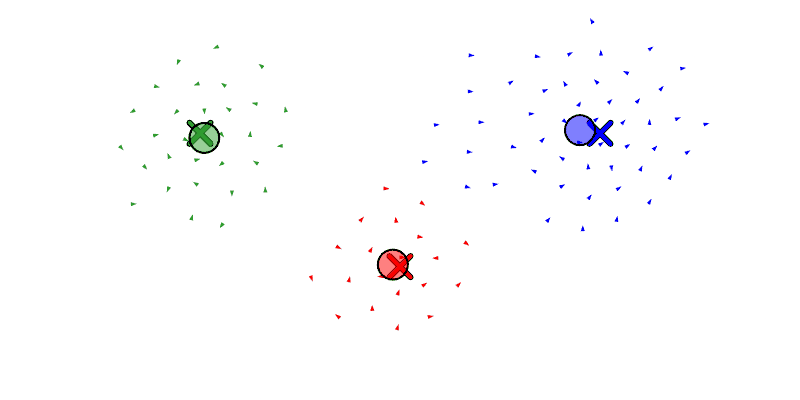
Let’s take a moment to improve the assignment algorithm, replacing the current random assignment with a position-aware assignment.
The Assignment Problem
I want the drones that get selected for a re-assignment (or fork) to be selected based on their position relative to the target location and current location. For example, if I wanted a swarm to split in half and move to the left and right, we want the drones on the left of the swarm to be the drones assigned to move to the left, and the drones on the right to be the ones assigned to move right.
This type of problem is well-known and called the Assignment Problem, and in the more general case, the Minimum-cost Flow Problem. As an example problem, let’s say we want to assign 2 drones to location A and 1 drone to location B. Framed as the Assignment Problem: We create 3 “tasks”, 2 for location A and 1 for location B, and now we have the Assignment Problem of matching 1-to-1 the drones to tasks, while minimizing the sum total cost (distance from each drone to its assigned location). Framed as the Minimum-cost Flow Problem: We look at each drone is a source of 1 flow, location A as a sink of 2 flow, location B as a sink of 1 flow, and edges connecting the sources and sinks with weights equal to the cost between each source and sink, then we have the Minimum-cost Flow Problem of assigning flows from sources to sinks while minimizing cost.
Typically you would use the distance between a drone and target as the cost, but I decided to use the square of the distance since I think the assignments are more visually appealing (maybe there’s some rigorous reason out there that justifies my aesthetic intuition, but for now it’s just for visual appeal). Below we see how 1000 points can be assigned equally among 5 targets, comparing the assignments produced from the normal distance cost to the squared distance cost.

And since our API only lets a swarm split into two swarms, our assignment problem is much simpler then the general problem and can be easily implemented. We can calculate a drones “re-assignment cost” of being re-assigned from location A to location B by taking the difference of costs to each location. Then we can pick all the drones with the lowest re-assignment cost as the drones to be re-assign.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
function reassign_drones(source_swarm, target_swarm, num_to_move):
# 1. collect all drones currently in the source swarm
candidates = source_swarm.drones
# 2. for each candidate, compute its “re-assignment cost”:
# how much cheaper (or more expensive) it is to go to target vs. stay
for each drone in candidates:
cost_to_target = squared_distance(drone.position, target_swarm.position)
cost_to_source = squared_distance(drone.position, source_swarm.position)
delta[d] = cost_to_target − cost_to_source
# 3. sort the candidates by that delta (lowest first)
sort candidates by delta ascending
# 4. pick the first num_to_move drones
to_reassign = first num_to_move elements of candidates
# 5. re-assign each one
for each drone in to_reassign:
drone.swarm = target_swarm
And here we see the same forking and re-assigning from before, but now with the position-aware assignment.
Additional Features
We’ll add in a few more things to make this prototype more interesting.
- No-fly zones: Rectangles that boids get repulsed by when they get too close. Obviously this could be more sophisticated (more general shapes, using path-finding instead of barrier functions), but this is the easiest first version.
- Circling: We allow the swarms to encircle a target instead of just hovering on top of it.
- Landmarks: Adds more objects in the scene that the user can work with.
- Phonetic IDs: Using the NATO phonetic alphabet to ID objects in the scene will make it easier to verbally issue commands.
- Coordinate grid: Overlaying a grid with coordinates on top of the screen lets the user more easily reason about coordinates.
Here we see all the features, with one swarm traveling through waypoints, another encircling a position, and another following a car around a no-fly zone.
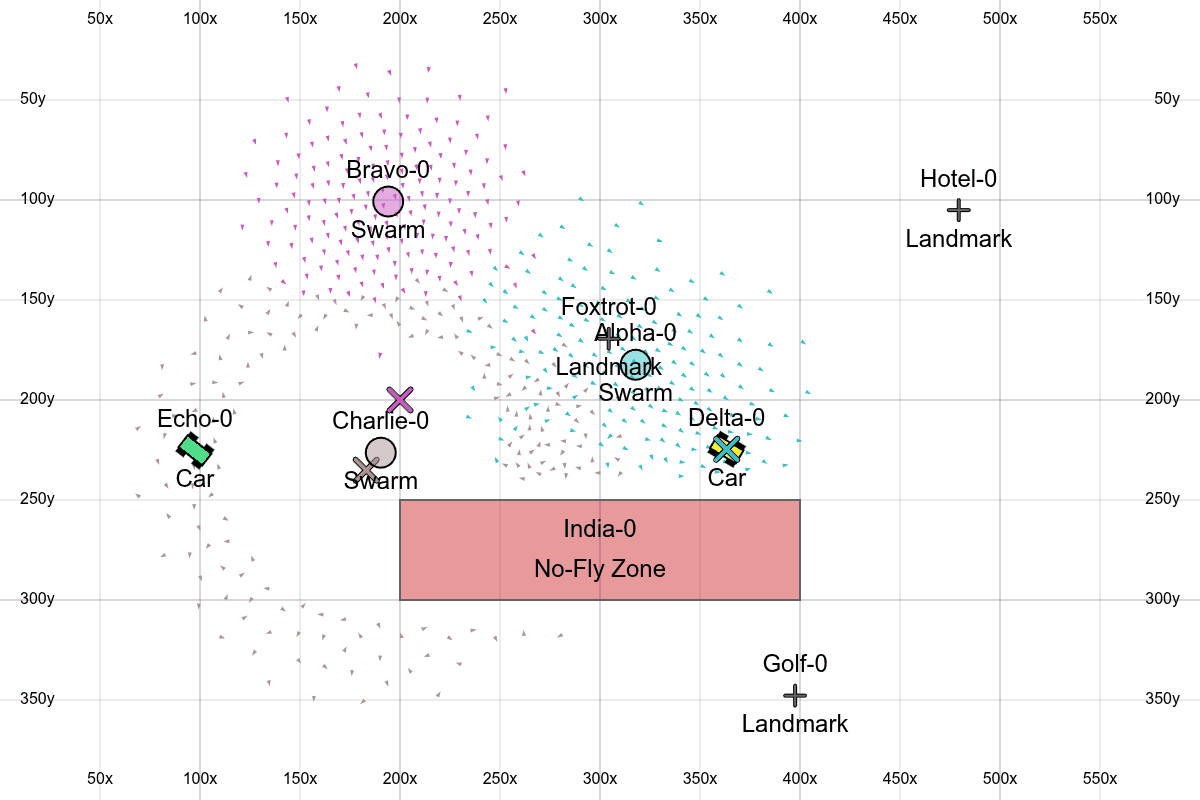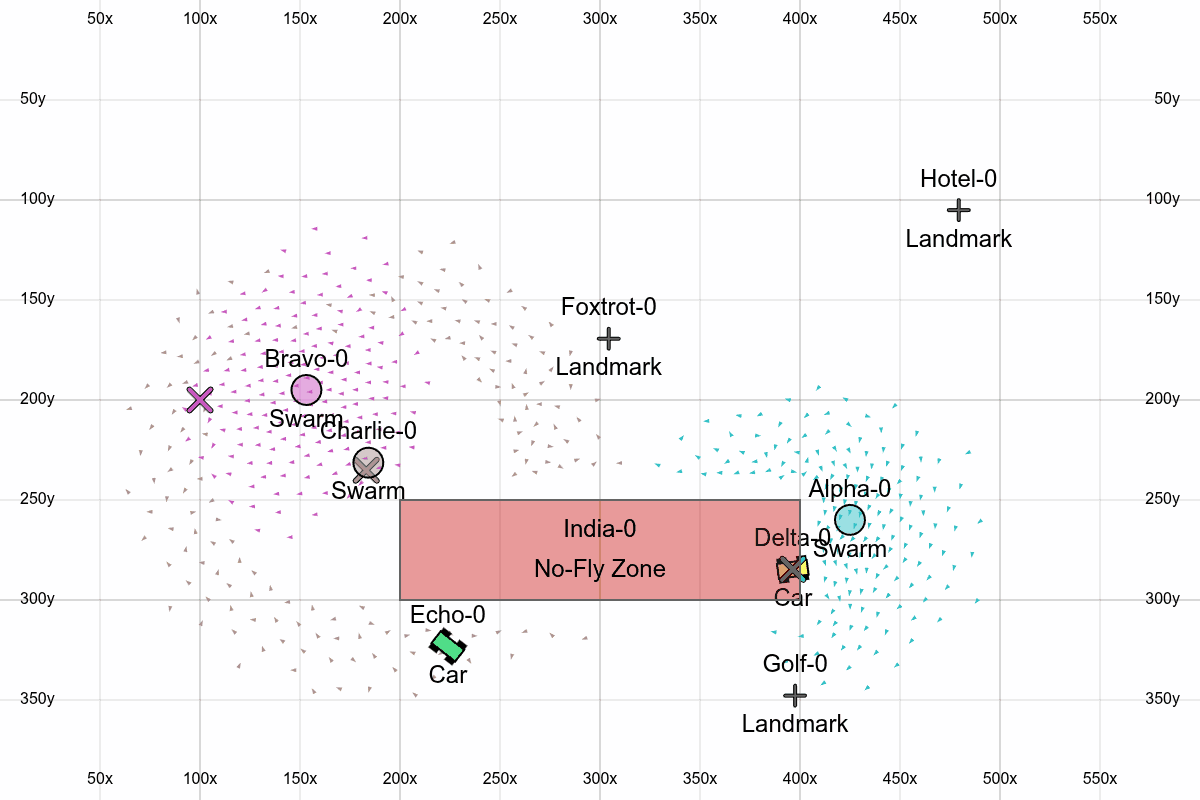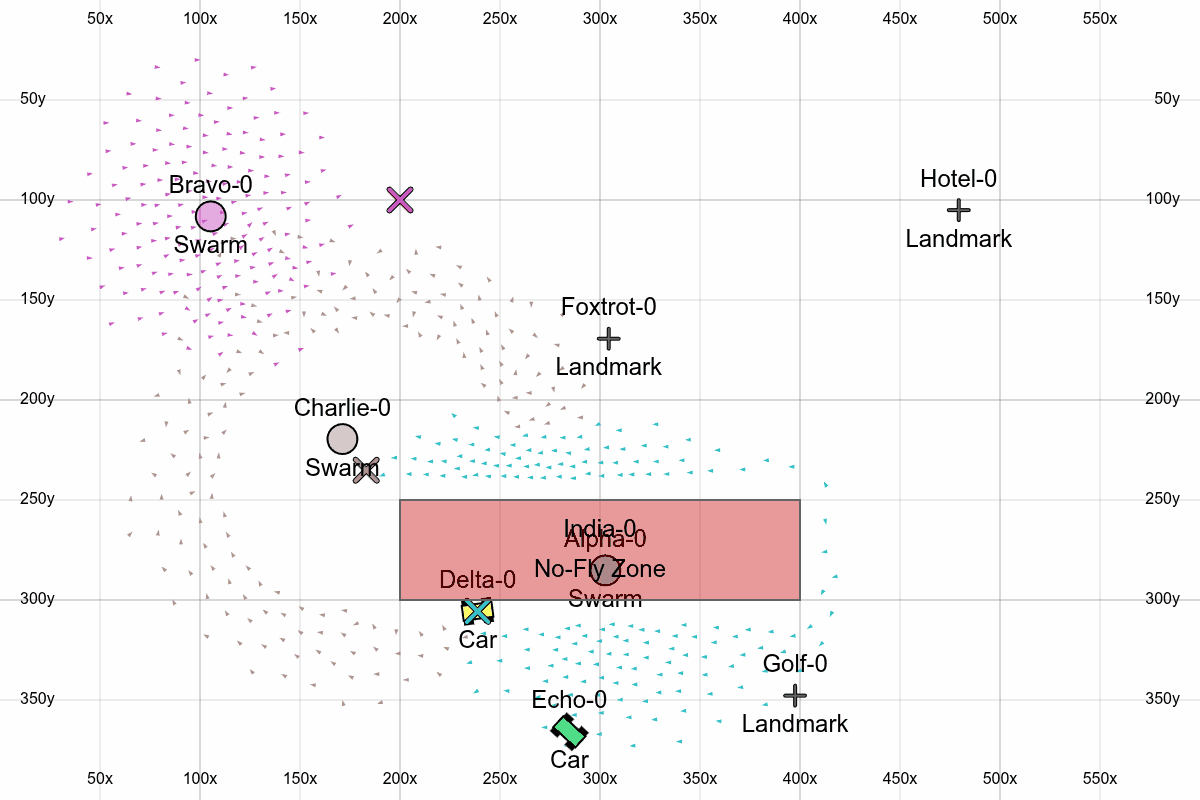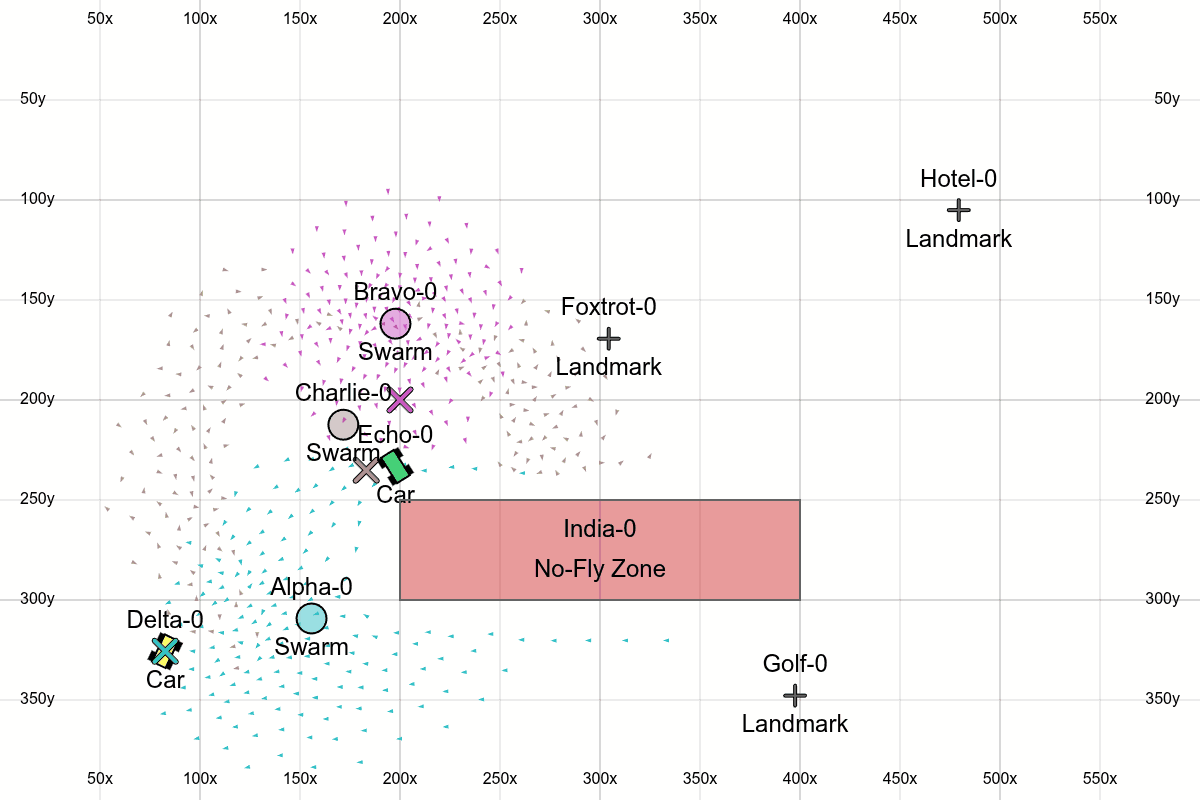
All together
So the tools that the agent will have access to are:
| Function Name | Arguments | Returns |
|---|---|---|
| get_environment | All objects in the scene | |
| assign_swarm_to_position | swarm_id, x, y | If the swarm was assigned |
| assign_swarm_to_waypoints | swarm_id, waypoints, cycle | If the swarm was assigned |
| assign_swarm_to_follow | swarm_id, target_id | If the swarm was assigned |
| fork_swarm_to_position | source_swarm_id, num_drones, x, y | The new swarms ID |
| fork_swarm_to_waypoints | source_swarm_id, num_drones, waypoints, cycle | The new swarms ID |
| fork_swarm_to_follow | source_swarm_id, num_drones, target_id | The new swarms ID |
| reassign_drones | source_swarm_id, target_swarm_id, num_drones | The number of drones actually re-assigned |
| merge_swarm | source_swarm_id, target_swarm_id | The target swarm ID |
| set_swarm_encircle | swarm_id, is_encircling, radius | The state of the swarms is_encircling |
And now we can try to control the swarms with our voice.
And the code for everything here can be found at my GitHub.