

Problem Statement
Today we create a scalable dynamic decentralized cluster identification protocol. An example to explain:

We have a large number of drones (colored circles) that can communicate with other nearby drones (communication is represented by expanding blue circles). We wish to assign a cluster ID (color) to all the drones in a cluster, a cluster being a connected set of drones (all drones that can communicate with each other, either directly or indirectly through other drones). I think of this as using the paint bucket in Photoshop, coloring a single node/droid and watching it spread through the graph/network across the links, repeating with a different color on an uncolored node, and so on until all nodes are colored.
But we want to avoid using an all-seeing entity such as ourselves, we want the drones to color themselves.
It must be decentralized, but that’s not all. It must be dynamic, meaning it can adapt to clusters that split or join together. We also want it to be scalable, considering potentially having millions of drones. Here are some reasonable constraints for scalability:
- The drones have limited memory, which means no storing the entire topology.
- The communication links have limited capacity, which means we can’t have every node flood filling the network all the time.
But anything else is acceptable, as long as nothing scales with the network size. For example, if you want to store the list of all two hops from yourself, that’s fine, since it won’t grow with the network (assuming networks expand outward rather than getting more dense).
An Easier Problem
Drones within a cluster must negotiate a cluster ID with all the other drones in their cluster, even the ones they aren’t directly connected to. Let’s ignore all the other requirements and use this as a simple problem to start with, how can a cluster of drones (not moving) agree on a value when they can only communicate with their neighbors? Give it a try before moving on.
One solution is to have every drone broadcast a random number, then have each drone pass along any received message to its neighbors, as well as store the message for itself, and then stop when no more messages have been received for a long time. At the end of this, everyone will have the same set of numbers (since every message was passed along to everyone in the cluster), which we will call the cluster-ID.
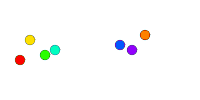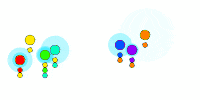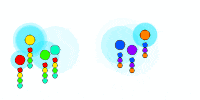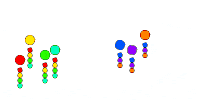
Here we show each drone picking a random number (its color) and flood-filling the network (the blue expanding circle). Below each drone, we show the list of received messages. This results in all drones within a cluster sharing the same set of received colors. But this is not a scalable solution, can you see why? Think of millions of drones in a cluster, what goes wrong?
Scaling
The last solution doesn’t scale for two reasons:
- Every drone has to store a number from every other drone, so local memory is required to scale with network size.
- Every drone will have its message passed over every link, so the link usage is scaling with network size.
Rather than first communicating all the numbers and taking the set, let’s use the highest value as the cluster-ID. This also allows us to prune incoming values when we receive an ID lower than the highest we have seen so far. When a drone receives a new number, it will either be higher than its current value, in which case it updates its value and passes it on, or the value is lower, in which case it can ignore it. Now a drone only has to store a single value at a time, and the links will quickly stop being used by any small numbers, which are immediately ignored.
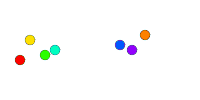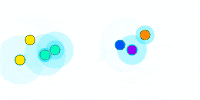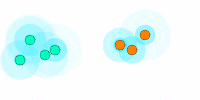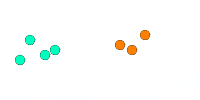
We see here how everyone quickly agrees on a value and different values for different clusters. This solves the scalability issue but doesn’t meet our requirement for dynamic clusters. Imagine if a cluster follows this process, then splits apart, the two clusters have no way of knowing they need to restart the process.
Dynamic Clusters
How does a drone know when it has left the cluster or joined a new one? Again, take a moment to consider before moving on.
If the drone that announced the highest number keeps track of that fact, then it can consider itself the cluster leader drone (this does not account for ties/duplicates, which we will go over later). The leader will periodically send out Keep-Alive messages like You are in cluster 14. This is all we need for drones to detect leaving and entering clusters.
When a drone leaves a cluster, it will no longer receive the Keep-Alive signal, which tells them they have left. When a drone hears two conflicting Keep-Alive signals like You are cluster 14 and You are cluster 61, it knows it has combined with a second cluster.
When a drone hears from two conflicting leaders, it will choose the one with the higher-numbered cluster-ID. This also means the leader from the cluster with a smaller ID must now become a follower.
When leaving a cluster, a drone will assume it is on its own and elect itself as the leader of its own cluster. If a drone left the old cluster with other drones, then all the drones in this new splinter cluster will temporarily elect themselves leaders, but only for a moment. Each new leader will announce their cluster ID, and then all but one drone will become a follower since only one drone picked the highest ID.

Here we started with a cluster of 4 drones which have a cluster ID represented as red. The cluster splits, causing the two left drones to stop hearing broadcasts from the red cluster leader (leaders are indicated with a bold outline). The two separated drones now elect themselves leaders and broadcast their new cluster-ID. One of the new leaders hears the other’s larger cluster-ID and joins that cluster, in this case, the blue cluster. This process repeats at a larger scale when the two clusters rejoin.
After speeding up the process and letting it run in a less controlled environment, we get the following.

And the pseudo-code being run on each drone is below. It doesn’t include logic to ignore messages that have already been seen, which needs to be added so you don’t get cycles of broadcasts (which likely looks like adding a nonce to each message and a queue of recently seen nonces to ignore).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
onceASecond():
if isLeader:
broadcastClusterID()
else:
if noReceivesInLongTime():
isLeader = true
currentClusterID = randomNumber()
onReceiveClusterID(incomingClusterID):
if incomingClusterID > currentClusterID:
currentClusterID = incomingClusterID
if isLeader:
isLeader = false
if incomingClusterID == currentClusterID:
broadcastClusterID()
Live Simulation
And for your enjoyment, an everlasting simulation of the boids running this algorithm.
That covers the main point of this post. The following are points of interest I think could use some more thinking, which I try to provide.
Remaining Issues
There are several issues left to resolve in this protocol.
Ties
Drones randomly pick a cluster ID, which means two drones could possibly pick the same random cluster-ID. This would prevent clusters from choosing a new cluster ID when they split (although only if each new cluster has one of the duplicate leaders).
There are at least two potential solutions to this. The first is to pre-assign every drone a unique ID, which can then be used in replacement of picking a random cluster ID every time. Although, this could violate the scalability requirement, and is generally unsatisfactory. The second solution is to have leaders listen for messages they didn’t send out (which they can already look for if using a nonce and queue to track previously seen messages), and upon recognizing there are duplicate leaders, pick a new random cluster-ID. A slight optimization is to have the new random cluster ID be larger, which means one of the two previous leaders will be the next leader, which avoids having the entire cluster re-elect a new leader (but make sure to do an entire re-election if both leaders tied with the largest possible cluster ID).
There is still an issue with ties between leaders not in the same cluster. There is no way for a drone to know what ID another cluster will pick since they pick at random, and cannot be communicated with. There is no way to resolve the issue until the clusters combine(unless again, you use pre-assigned unique IDs).
Missed messages
The user must specify how long is “too long” for a drone to wait for a Keep-Alive message.
If they specify a short threshold, then you may get unstable clusters due to the natural delays introduced in real-world networks. While unlikely, if a node is traveling quickly in the same direction that a Keep-Alive message is propagating through the network, it may take longer than usual to receive messages (a sort of Doppler effect), which causes the Keep-Alive signal to arrive at longer intervals.
If they specify a long threshold, then a drone may actually leave the cluster for a time, miss some messages, and rejoin without realizing they were disconnected. One way to fix this is to have drones periodically check if their neighbor has the same recent history as themselves, looking back for at least the amount of time a drone can leave the cluster.
Alternatively, we can attach to each Keep-Alive message a counter that increments after each message broadcast. When a drone receives a message with a counter greater than expected, it will know it left the cluster temporarily. This can fail if a drone moves from being far (speaking in terms of hops) from the leader to suddenly being much closer. All the messages still on their way to the once-distant drone will take longer than the most recent message.
Collision avoidance
When a drone is broadcasting, it is sending out radio signals at a specified frequency which the other drones know to listen to. When two drones broadcast at the same time, their signals will collide with each other, causing the messages to get corrupted. Many wireless networks solve this by using Carrier-sense Multiple Access with Collision Avoidance (CSMA C/A). This is a nice solution to the collision issue but only solves the problem for nodes within a short distance of each other. We still face the Hidden Node Problem, which is when two drones that are out of range with each other broadcast to a drone in the center of the two, causing the message to collide only at the central drone. To solve this, some wireless networks use Request to Send/Clear to Send (RTS/CTS), but this is for sending a message to a central drone, not broadcasting. One potential solution to this problem is a recent MAC protocol called A Dynamic Distributed Multi-Channel TDMA Slot Management Protocol for Ad Hoc Networks, which solves both the hidden node problem, the exposed node problem, and adapts to interfering networks. Although, this protocol focuses on node-to-node communication rather then broadcasts, but I believe it could be modified for a flood fill setting.
Unstable clusters
When we have a large cluster, some nodes will leave and rejoin. Each time they do this they generate a new proposed cluster ID, which if greater then the current cluster ID, will change the whole cluster. We have a similar issue with new drones entering the cluster, although this is less significant as it does not persist over time.
We can calculate how often we expect a cluster to change IDs, if you’re into that sort of thing.
If you pick $N$ random numbers, there is an equal chance for each number being the largest of the $N$, which is a $\frac{1}{N}$ chance. Every time the $i$th ID proposal is made, there is a $\frac{1}{i}$ chance it is the largest, and therefor changes the cluster ID. This means for $M$ sequential proposals, the expected number of ID changes is $\frac{1}{1} + \frac{1}{2} + … + \frac{1}{M}$, which is the well known Harmonic Series.
The Harmonic Series is known to be approximated by $\text{ln}(n) + 0.577$. This tells us that the number of cluster ID changes grows logarithmically with the number of new cluster ID proposals.
This all assumes each new cluster ID is proposed one at a time, which may not be true. Initial cluster formation may already have a number of drones, in which case all of the drones vote at once. This would not mean they only change cluster IDs once, but requires an interesting new analysis where we look at the problem geometrically as expanding circles, then ask how many circles cross over a point on average?
This first analysis is still useful though. At large cluster sizes we do expect drones to be “bubbling” at the edges, which provides a near constant flow of ID proposals. In such a situation we expect the cluster ID to change logarithmically with time (or proposal count, same thing here).
It would be nice to solve this issue by having the largest cluster always win a cluster merge, but I have not found a scalable algorithm to have every drone in a cluster know the size of the cluster it is in. Another solution is needed.
Instead of size, what if we have the oldest cluster win? This would at least solve the issue of drones “bubbling” at the edges. If we assume that all drones share a universal clock, then each leader can attach the time of cluster creation to its keep-alive message, and followers follow the leader with the oldest cluster. The assumption that all drones share a universal clock is unsatisfactory, so we discard it. If we instead only assume consistent timers (no drift) on all drones (more satisfactory, but still sub-optimal), each cluster may attach to the keep-alive the number of seconds the cluster has been alive, then followers follow the cluster with the longest lifetime. This may seem the same as the universal clock solution, but it is not, as we will see.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
onceASecond():
if isLeader:
currentClusterLifetime += 1
broadcastClusterID()
else:
if noReceivesInLongTime():
// creating a new cluster
isLeader = true
currentClusterLifetime = 0
currentClusterID = randomNumber()
onReceiveClusterPayload(incomingClusterLifetime, incomingClusterID):
if not fromCurrentOrSuperiorCluster(incomingClusterLifetime, incomingClusterID):
return // ignore inferior cluster payloads
currentClusterLifetime = incomingClusterLifetime
currentClusterID = incomingClusterID
if isLeader:
isLeader = false
broadcastClusterPayload()
fromCurrentOrSuperiorCluster(incomingClusterLifetime, incomingClusterID):
if incomingClusterLifetime > currentClusterLifetime:
return true
if incomingClusterLifetime == currentClusterLifetime and \
incomingClusterID > currentClusterID:
return true
return false

There is a serious issue here, the clusters don’t always agree on the leader. The issue is that it takes time for a message to reach the edges of a cluster and the message has gotten old by that time. The difference between the universal clock solution and the lifetime solution becomes relevant here. The lifetime solution sends out messages that carry the number of seconds the cluster has been alive, which becomes more outdated the longer the message takes to propagate. The universal clock solution sends out messages that carry the time a cluster was formed, which does not get outdated, regardless of how long a message takes to propagate.
One solution for the lifetime strategy is to try and approximate the true age of the cluster by counting the number of hops a message has taken to reach a drone. By assuming each hop has a perfectly consistent latency and that each message contains the number of hops the message has taken, then the true lifetime $=$ lifetime in message $+$ hops from leader $*$ latency per hop.
Instead, we could try for the universal clock, and attempt to alleviate some of the unsatisfaction. Instead of assuming everyone shares a clock at the outset, we have drones synchronize their clocks upon contact with each other. The older clock replaces the younger clock, allowing the oldest clock to spread like a perfect virus, spreading through every possible path in space and time. Eventually, almost every drone would agree on a “universal” time. One issue that can occur is when two clusters meet for the first time, where the older cluster may lose when it shouldn’t since the clocks need to synchronize first. This is mitigated by making sure to first have the clocks synchronize, update the cluster lifetime accordingly, and then compare the cluster lifetimes to see who should win a merge.
The only truly satisfactory solution is to have the largest cluster win. I still haven’t found a scalable and dynamic protocol to answer this question, which seems to me to be a fairly fundamental piece of information for a drone to have about its cluster. Please reach out if you have ideas, I think it should be an interesting problem to solve.